In this post I'm showing an example of spatial data in combination with
the Data Vault methodology based on the philosophy implemented at our
company. There are several philosophies how to model your Enterprise Data Warehouse using Data Vault (DV), and each philosophy has its merits and its drawbacks. This blog isn't meant to discuss these philosophies: there are
far more suitable blogs for that. Instead, we're going to focus on one specific item regarding Data Vault, namely: how to incorporate spatial data in the Data Vault method. Data Vault consists of three main components, being hubs, links and satellites. Hubs contain the business entities, links contain the relationships between business entities and the satellites contain the context of hubs and links.
So, how does Data Vault handle spatial data? The geometry attributes of an object provide context about the location of the object in the real world. Most RDBMS support spatial information as a specific object type. So at this point it is safe to assume that geometry will find its place in the data vault. But, as we've seen in a previous
post, geometry also provides spatial reference to other objects. In other words, it forms relationships between objects. Will this affect the way DV handles spatial data
The example
In our architecture we are using a raw data vault that serves as a technical copy of the source systems. Prior to loading the raw data vault, source systems are copied to a staging area. After loading, data is processed into several data marts that are accessed by end users through reporting, analysis (OLAP) and, in the near future, dashboard solutions.
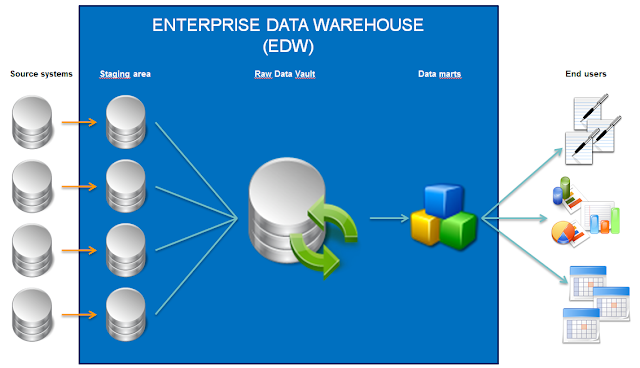 |
| Our Enterprise BI architecture |
As I said, it is one of several philosophies. This is a fairly technical approach, with the benefit that a lot of work building the EDW can be automated. The routines needed for loading the staging areas and the raw data vault are generated with the use of the DV modeling tool
Quipu (which was open source at the time we started building our EDW). The manual labor required to transform the data for end user purposes (the big T) is offloaded to the data mart phase.
#1: Import the source system
For this demo, I've created a new example source system with 4 spatial tables selected from our company geodatabase, containing incidents, maintenance areas, and the border of our service area both as line an polygon (which are in two separate tables). All 4 tables contain a GEOMETRY type column, named either LIGGING or GEOM.
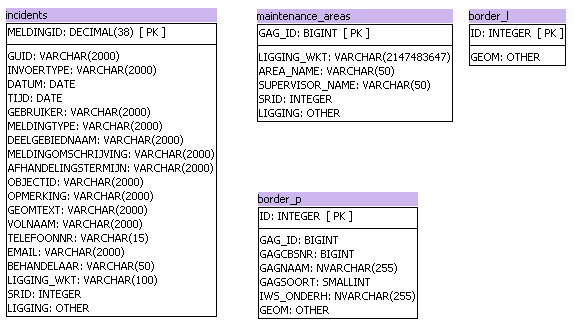 |
| Spatial source system model example |
The source system model is imported into Quipu. The first thing we notice is that Quipu doesn't recognize geometry type columns. We need edit the column type and native type manually.
 |
| Source model in Quipu, with geometry type manually altered |
#2: Loading the staging area
The next step, we're creating the staging area which is a copy of the source with some added metadata fields. The appropriate staging area DDL and ETL is generated by Quipu. Let's take a look at the DDL-code for the maintenance areas table below.
CREATE TABLE edw.sta_spatial.maintenance_areas
( GAG_ID bigint
, LIGGING_WKT varchar(MAX)
, AREA_NAME varchar(50)
, SUPERVISOR_NAME varchar(50)
, SRID int
, ligging geometry
, stg_timestamp DATETIME DEFAULT CURRENT_TIMESTAMP
, stg_sequence INT DEFAULT 1
, voided BIT DEFAULT 0
, audit_id INT
);
As we notice,the DDL is generated using the correct geometry type field after we manually altered it in the previous step. With the DDL, we can create the proper staging area tables without any further edits.
In this process, Quipu also generated the ETL needed to fill the staging area. In our case, this ETL consists of Pentaho Data Integration (PDI) code. As explained in an earlier
post, PDI can support geometry type fields. Unfortunately, PDI only offers support for geometry type in combination with Oracle and PostgreSQL. Since our EDW is built on the MS SQL Server platform, we needed to create a workaround for this. We solved this by inserting the geometry into the staging area in well-known text format (stored in the field LIGGING_WKT) and converting it to spatial with an 'INSTEAD OF'-trigger we are able to fill the staging properly.
CREATE TRIGGER [dbo].[maintenance_areas_trg] ON [dbo].[maintenance_areas]
INSTEAD OF INSERT
AS
BEGIN
INSERT INTO maintenance_areas (
[GAG_ID]
,[LIGGING_WKT]
,[AREA_NAME]
,[SUPERVISOR_NAME]
,[SRID]
,[ligging]
) SELECT
[GAG_ID]
,[LIGGING_WKT]
,[AREA_NAME]
,[SUPERVISOR_NAME]
,[SRID]
,geometry::STGeomFromText ( LIGGING_WKT , 28992 )
FROM
INSERTED
END
The insertion of the field 'LIGGING' is bypassed by the trigger. In the code above,we can see the field is filled by converting text to actual geometry with use of the MS SQL command STGeomFromText.
This is not the only possible solution. There are several other solutions for this problem, ranging from using another ETL-tool to fill the staging area to changing EDW database platform. For now, we can suffice with the notion that filling the staging area with spatial data is possible.
#3: Designing the raw data vault
The next step in this example consists of modeling the raw data vault. Our modeling software Quipu will automatically generate a data vault style model based on the technical properties of the staging area. It also allows us to manually identify the business key in the staging tables that lack a primary key in the source model.
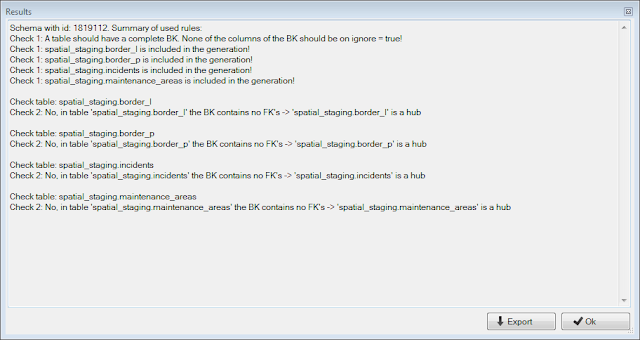 |
| Generating the spatial raw data vault example |
After analyzing our source model (shown above in paragraph #1), Quipu generates a data vault model consisting of 4 hubs and corresponding satellites. The geometry type fields (highlighted in green) have become part of the satellites, which is logical as they are identified as context properties.
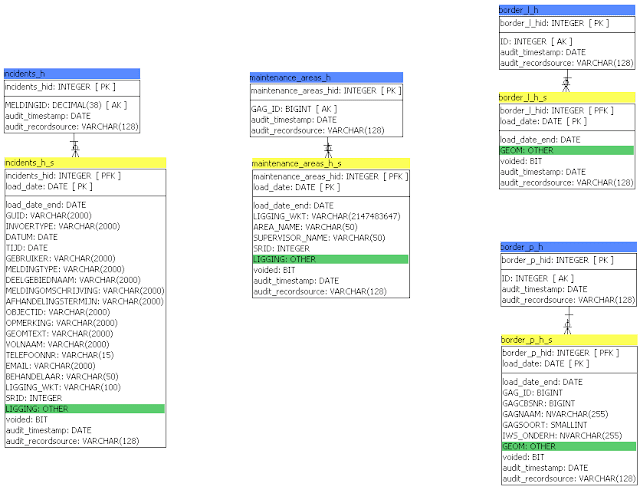 |
| Spatial raw data vault model based on example source system |
Notice the absence of any links in this model? As I explained in previous posts (
here and
here), geographical databases rely heavily on the implicit spatial relationships to tie data together. However, when generating a raw data vault using a logical rule engine, it will ignore these spatial relationships. As far as a raw data vault is concerned, this is correct behavior. As a consequence, geographical data sources with 100+ tables will inevitably be generated into raw data vaults with 100+ hubs and satellites and virtually no links.
After generating the model, we can continue with generating the DDL and ETL necessary to create the model in our EDW environment. The DDL below shows the generation of the maintenance areas hub and satellite, including the geometry field in the satellite. The generated DDL is flawless because we altered the type and native type column for the geometry field named 'LIGGING' manually in step #1.
CREATE TABLE edw.sdv_spatial.maintenance_areas_h
( maintenance_areas_hid INT NOT NULL IDENTITY(1,1)
, GAG_ID bigint
, audit_timestamp DATETIME
, audit_recordsource VARCHAR(128)
, CONSTRAINT pk_maintenance_areas_h
PRIMARY KEY( maintenance_areas_hid
)
);
CREATE UNIQUE INDEX bk_maintenance_areas_h ON edw.sdv_spatial.maintenance_areas_h
( GAG_ID
);
CREATE TABLE edw.sdv_spatial.maintenance_areas_h_s
( maintenance_areas_hid INT NOT NULL
, load_date DATETIME NOT NULL
, load_date_end DATETIME DEFAULT '9999-12-31'
, LIGGING_WKT varchar(MAX)
, AREA_NAME varchar(50)
, SUPERVISOR_NAME varchar(50)
, SRID int
, ligging geometry
, voided BIT
, audit_timestamp DATETIME
, audit_recordsource VARCHAR(128)
, CONSTRAINT pk_maintenance_areas_h_s
PRIMARY KEY( maintenance_areas_hid
, load_date
)
);
CREATE INDEX pd_maintenance_areas_h_s ON edw.sdv_spatial.maintenance_areas_h_s
( load_date
, load_date_end
);
We also generate the ETL steps that are needed to make the data vault run. These steps compare new data loaded into the staging area with the data already present in the raw data vault, identifying alterations and storing them into the data vault.
-- insert new business keys data from 'maintenance_areas' into 'maintenance_areas_h'
INSERT INTO edw.sdv_spatial.maintenance_areas_h
( GAG_ID
, audit_timestamp
, audit_recordsource
)
SELECT DISTINCT GAG_ID
, CURRENT_TIMESTAMP
, 'edw.sta_spatial.maintenance_areas'
FROM edw.sta_spatial.maintenance_areas stg
WHERE NOT EXISTS (SELECT 1
FROM edw.sdv_spatial.maintenance_areas_h
WHERE (stg.GAG_ID = GAG_ID OR (stg.GAG_ID IS NULL AND GAG_ID IS NULL))
)
;
-- insert new business keys data from 'maintenance_areas' into 'maintenance_areas_h_s'
INSERT INTO edw.sdv_spatial.maintenance_areas_h_s
( maintenance_areas_hid
, load_date
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
, audit_timestamp
, audit_recordsource
)
SELECT maintenance_areas_hid
, stg_timestamp
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
, CURRENT_TIMESTAMP
, 'edw.sta_spatial.maintenance_areas'
FROM ( SELECT (SELECT MAX(maintenance_areas_hid)
FROM edw.sdv_spatial.maintenance_areas_h
WHERE (src.GAG_ID = GAG_ID OR (src.GAG_ID IS NULL AND GAG_ID IS NULL))
) as maintenance_areas_hid
, stg_timestamp
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
FROM edw.sta_spatial.maintenance_areas src
) stg
WHERE NOT EXISTS (SELECT 1
FROM edw.sdv_spatial.maintenance_areas_h_s dv
WHERE (stg.maintenance_areas_hid = maintenance_areas_hid OR (stg.maintenance_areas_hid IS NULL AND maintenance_areas_hid IS NULL))
AND (stg.LIGGING_WKT = LIGGING_WKT OR (stg.LIGGING_WKT IS NULL AND LIGGING_WKT IS NULL))
AND (stg.AREA_NAME = AREA_NAME OR (stg.AREA_NAME IS NULL AND AREA_NAME IS NULL))
AND (stg.SUPERVISOR_NAME = SUPERVISOR_NAME OR (stg.SUPERVISOR_NAME IS NULL AND SUPERVISOR_NAME IS NULL))
AND (stg.SRID = SRID OR (stg.SRID IS NULL AND SRID IS NULL))
AND ((stg.ligging.STEquals(ligging) = 1) OR (stg.ligging IS NULL AND ligging IS NULL))
AND (stg.voided = voided OR (stg.voided IS NULL AND voided IS NULL))
AND load_date = (SELECT MAX(load_date)
FROM edw.sdv_spatial.maintenance_areas_h_s
WHERE maintenance_areas_hid = dv.maintenance_areas_hid
)
)
;
-- insert deleted business keys data from 'maintenance_areas' into 'maintenance_areas_h_s
-- entries in the edw.dbo.edw_load with is_full_load = 1 are treated as full loads!
INSERT INTO edw.sdv_spatial.maintenance_areas_h_s
( maintenance_areas_hid
, load_date
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
, audit_timestamp
, audit_recordsource
)
SELECT maintenance_areas_hid
, COALESCE(ld.load_timestamp,CURRENT_TIMESTAMP)
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, 1
, CURRENT_TIMESTAMP
, 'edw.sta_spatial.maintenance_areas'
FROM edw.sdv_spatial.maintenance_areas_h_s dv
INNER
JOIN edw.dbo.edw_load ld
ON ld.table_name = 'edw.sta_spatial.maintenance_areas'
AND ld.is_full_load = 1
WHERE load_date = (SELECT MAX(load_date)
FROM edw.sdv_spatial.maintenance_areas_h_s
WHERE maintenance_areas_hid = dv.maintenance_areas_hid
)
--AND dv.voided = 0
AND dv.voided = 0
AND NOT EXISTS (SELECT 1
FROM edw.sta_spatial.maintenance_areas src
LEFT OUTER HASH
JOIN edw.sdv_spatial.maintenance_areas_h t1821432
ON (t1821432.GAG_ID = src.GAG_ID OR (t1821432.GAG_ID IS NULL AND src.GAG_ID IS NULL))
WHERE t1821432.maintenance_areas_hid = dv.maintenance_areas_hid
)
;
-- Satellite end dating in 'maintenance_areas_h_s'
UPDATE edw.sdv_spatial.maintenance_areas_h_s
SET load_date_end = (SELECT MIN(s.load_date)
FROM edw.sdv_spatial.maintenance_areas_h_s s
WHERE s.maintenance_areas_hid = edw.sdv_spatial.maintenance_areas_h_s.maintenance_areas_hid
AND s.load_date > edw.sdv_spatial.maintenance_areas_h_s.load_date
)
WHERE load_date_end = '9999-12-31' -- in ISO 8601 format
AND (SELECT MIN(s.load_date_end)
FROM edw.sdv_spatial.maintenance_areas_h_s s
WHERE s.maintenance_areas_hid = edw.sdv_spatial.maintenance_areas_h_s.maintenance_areas_hid
AND s.load_date > edw.sdv_spatial.maintenance_areas_h_s.load_date
) IS NOT NULL
;
This code needs one small but crucial alteration for each satellite that is generated. The code that updates the new business keys data into the satellite compares the existing data with the new data that is loaded into the staging area, based on an '=' comparison. This operator won't work for geometry type fields. Instead, the database platform offers specific operators for handling spatial data. Let's take a closer look at the satellite insert statement.
-- insert new business keys data from 'maintenance_areas' into 'maintenance_areas_h_s'
INSERT INTO edw.sdv_spatial.maintenance_areas_h_s
( maintenance_areas_hid
, load_date
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
, audit_timestamp
, audit_recordsource
)
SELECT maintenance_areas_hid
, stg_timestamp
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
, CURRENT_TIMESTAMP
, 'edw.sta_spatial.maintenance_areas'
FROM ( SELECT (SELECT MAX(maintenance_areas_hid)
FROM edw.sdv_spatial.maintenance_areas_h
WHERE (src.GAG_ID = GAG_ID OR (src.GAG_ID IS NULL AND GAG_ID IS NULL))
) as maintenance_areas_hid
, stg_timestamp
, LIGGING_WKT
, AREA_NAME
, SUPERVISOR_NAME
, SRID
, ligging
, voided
FROM edw.sta_spatial.maintenance_areas src
) stg
WHERE NOT EXISTS (SELECT 1
FROM edw.sdv_spatial.maintenance_areas_h_s dv
WHERE (stg.maintenance_areas_hid = maintenance_areas_hid OR
(stg.maintenance_areas_hid IS NULL AND maintenance_areas_hid IS NULL))
AND (stg.LIGGING_WKT = LIGGING_WKT OR (stg.LIGGING_WKT IS NULL AND LIGGING_WKT IS NULL))
AND (stg.AREA_NAME = AREA_NAME OR (stg.AREA_NAME IS NULL AND AREA_NAME IS NULL))
AND (stg.SUPERVISOR_NAME = SUPERVISOR_NAME OR (stg.SUPERVISOR_NAME IS NULL AND SUPERVISOR_NAME IS NULL))
AND (stg.SRID = SRID OR (stg.SRID IS NULL AND SRID IS NULL))
AND ((stg.ligging.STEquals(ligging) = 1) OR (stg.ligging IS NULL AND ligging IS NULL))
AND (stg.voided = voided OR (stg.voided IS NULL AND voided IS NULL))
AND load_date = (SELECT MAX(load_date)
FROM edw.sdv_spatial.maintenance_areas_h_s
WHERE maintenance_areas_hid = dv.maintenance_areas_hid
)
)
;
Highlighted in green we see the part where the newly inserted geometries are being compared to the geometry data already present in our data vault. In the Quipu generated statement, they were simply compared using the '=' operator, which won't work. So we alter the statement slightly using the MS SQL specific statement
STEquals (other RDBMS support the same statement, but with different syntax). This statement compares the actual spatial data stored in the two geometry fields. This small edit needs to be done for each satellite ETL that is generated. In our example this means altering four SQL statements. After this edit, our generated ETL will work as expected, identifying all altered objects in our staging area.
Conclusion
When integrating spatial data in a raw data vault style EDW, there are two important questions to consider:
- Does my ETL tooling support spatial object types?
- What alterations do I have to make to my code?
This example shows us that, with some minor alterations to our code, we can easily adapt a raw data vault to support storing and tracking spatial attribute information. In the next post, we will take a look at spatial in the business data vault.


































